- Настройка кодировки шрифтов в cmd/bat (иероглифы, кракозябры)
- Исправляем проблему с кодировкой с помощью смены шрифта
- Исправляем проблему с кодировкой с помощью смены кодировки
- Как исправить отображение кириллицы или кракозябры в Windows 10
- Исправление отображения кириллицы с помощью настроек языка и региональных стандартов Windows 10
- Как исправить иероглифы Windows 10 путем изменения кодовых страниц
- С помощью редактора реестра
- Путем подмена файла кодовой страницы на c_1251.nls
- HackWare.ru
- Этичный хакинг и тестирование на проникновение, информационная безопасность
- Как быстро узнать и преобразовать кодировку
- Как определить кодировку
- URL кодировка
- Base64
- Кодировка UTF-8
- Экранированные последовательности
- Как конвертировать в экранированные последовательности
- Как изменить кодировку строки или документа без сторонних сервисов
 Настройка кодировки шрифтов в cmd/bat (иероглифы, кракозябры)
Настройка кодировки шрифтов в cmd/bat (иероглифы, кракозябры)
 Настройка кодировки шрифтов в cmd/bat (иероглифы, кракозябры)
Настройка кодировки шрифтов в cmd/bat (иероглифы, кракозябры)
В некоторых случаях, когда используется неверная кодировка, могут возникать так называемые кракозябры или иероглифы, т.е. не читаемые символы, которые невозможно разобрать при работе с командной строкой. Эти проблемы могут также возникать и при запуске различных BAT-файлов. В данной статье мы расскажем о том, как можно сменить шрифт или кодировку, чтобы избавиться от этой проблемы. Пример таких не читаемых символов можно видеть на картинке ниже: 
Исправляем проблему с кодировкой с помощью смены шрифта
Первым делом нужно зайти в свойства окна: Правой кнопкой щелкнуть по верхней части окна -> Свойства -> в открывшемся окне в поле Шрифт выбрать Lucida Console и нажать кнопку ОК.
После этого не читаемые символы должны исчезнуть, а текст должен выводиться на русском языке.
Исправляем проблему с кодировкой с помощью смены кодировки
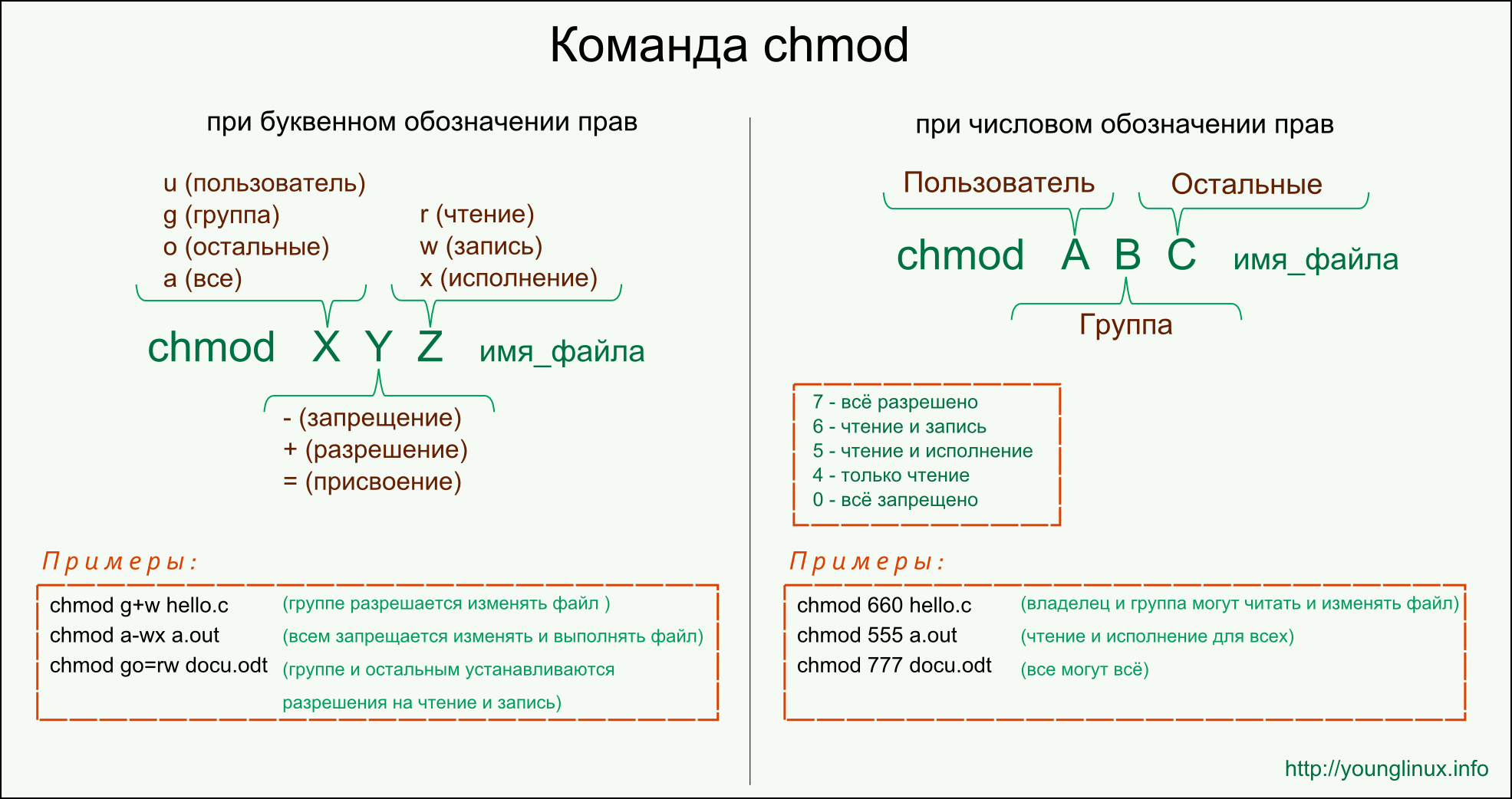
Вместо смены шрифта, можно сменить кодировку, которая используется при работе cmd.exe.
Узнать текущую кодировку можно введя в командной строке команду chcp , после ввода данной команды необходимо нажать Enter . 
Как видно на скриншоте, текущая используемая кодировка Windows-1251
Для изменения кодировки нам необходимо воспользоваться командой chcp , где — это сам код кодировки, на которую мы хотим переключиться. Возможные значения:
- 1251 — Windows-кодировка (Кириллица);
- 866 — DOS-кодировка;
- 65001 — Кодировка UTF-8;
Т.е. для смены кодировки на DOS, команда примет следующий вид:
Для смены кодировки на UTF-8, команда примет следующий вид:
Для смены кодировки на Windows-1251, команда примет следующий вид:
Как исправить отображение кириллицы или кракозябры в Windows 10
Одна из возможных проблем, с которыми можно столкнуться после установки Windows 10 — кракозябры вместо русских букв в интерфейсе программ, а также в документах. Чаще неправильное отображение кириллицы встречается в изначально англоязычных и не совсем лицензионных версиях системы, но бывают и исключения.
В этой инструкции — о том, как исправить «кракозябры» (или иероглифы), а точнее — отображение кириллицы в Windows 10 несколькими способами. Возможно, также будет полезным: Как установить и включить русский язык интерфейса в Windows 10 (для систем на английском и других языках).
Исправление отображения кириллицы с помощью настроек языка и региональных стандартов Windows 10
Самый простой и чаще всего работающий способ убрать кракозябры и вернуть русские буквы в Windows 10 — исправить некоторые неправильные настройки в параметрах системы.
Для этого потребуется выполнить следующие шаги (примечание: привожу также названия нужных пунктов на английском, так как иногда необходимость исправить кириллицу возникает в англоязычных версиях системы без нужды менять язык интерфейса).
- Откройте панель управления (для этого можно начать набирать «Панель управления» или «Control Panel» в поиске на панели задач.
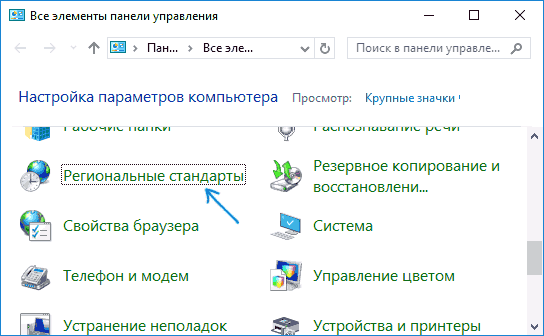
- Убедитесь, что в поле «Просмотр» (View by) установлено «Значки» (Icons) и выберите пункт «Региональные стандарты» (Region).
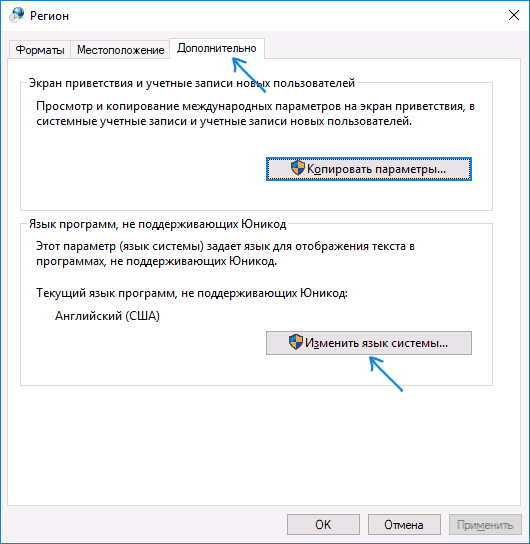
- На вкладке «Дополнительно» (Administrative) в разделе «Язык программ, не поддерживающих Юникод» (Language for non-Unicode programs) нажмите по кнопке «Изменить язык системы» (Change system locale).
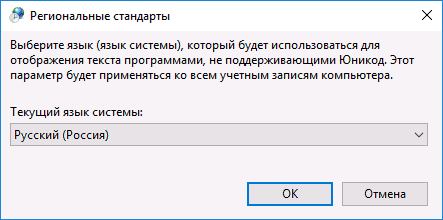
- Выберите русский язык, нажмите «Ок» и подтвердите перезагрузку компьютера.
После перезагрузки проверьте, была ли решена проблема с отображением русских букв в интерфейсе программ и (или) документах — обычно, кракозябры бывают исправлены после этих простых действий.
Как исправить иероглифы Windows 10 путем изменения кодовых страниц
Кодовые страницы представляют собой таблицы, в которых определенным байтам сопоставляются определенные символы, а отображение кириллицы в виде иероглифов в Windows 10 связано обычно с тем, что по умолчанию задана не та кодовая страница и это можно исправить несколькими способами, которые могут быть полезны, когда требуется не изменять язык системы в параметрах.
С помощью редактора реестра
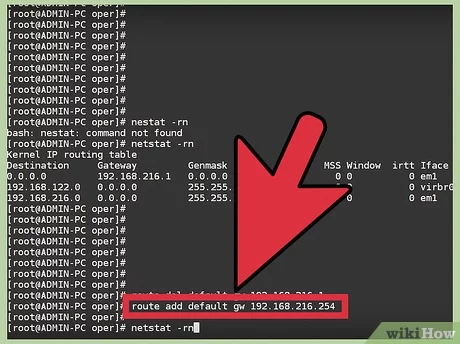
Первый способ — использовать редактор реестра. На мой взгляд, это самый щадящий для системы метод, тем не менее, рекомендую создать точку восстановления прежде чем начинать. Совет про точки восстановления относится и ко всем последующим способам в этом руководстве.
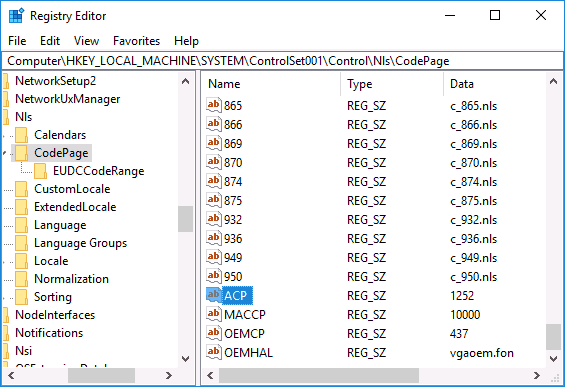
- Нажмите клавиши Win+R на клавиатуре, введите regedit и нажмите Enter, откроется редактор реестра.
- Перейдите к разделу реестраи в правой части пролистайте значения этого раздела до конца.
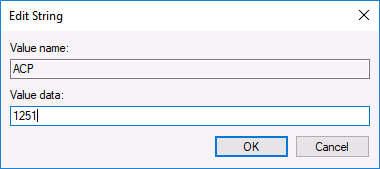
- Дважды нажмите по параметру ACP, установите значение 1251 (кодовая страница для кириллицы), нажмите Ок и закройте редактор реестра.
- Перезагрузите компьютер (именно перезагрузка, а не завершение работы и включение, в Windows 10 это может иметь значение).
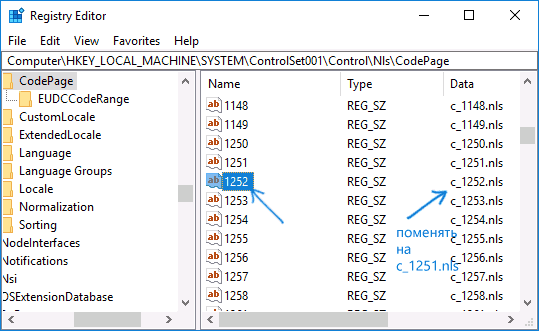
Обычно, это исправляет проблему с отображением русских букв. Вариация способа с помощью редактора реестра (но менее предпочтительная) — посмотреть на текущее значение параметра ACP (обычно — 1252 для изначально англоязычных систем), затем в том же разделе реестра найти параметр с именем 1252 и изменить его значение с c_1252.nls на c_1251.nls.
Путем подмена файла кодовой страницы на c_1251.nls
Второй, не рекомендуемый мной способ, но иногда выбираемый теми, кто считает, что правка реестра — это слишком сложно или опасно: подмена файла кодовой страницы в C:\ Windows\ System32 (предполагается, что у вас установлена западно-европейская кодовая страница — 1252, обычно это так. Посмотреть текущую кодовую страницу можно в параметре ACP в реестре, как было описано в предыдущем способе).
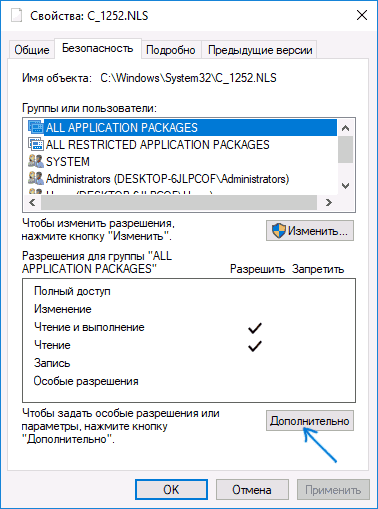
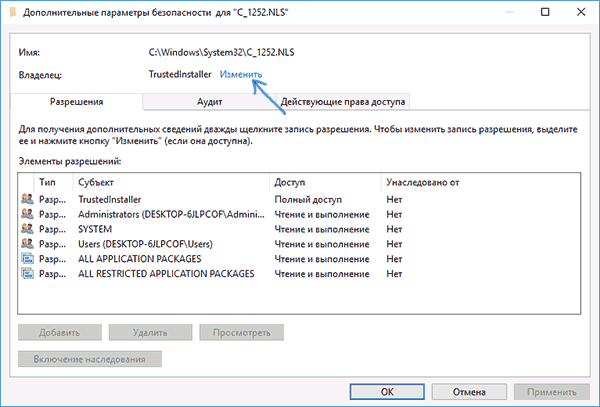
- Зайдите в папку C:\ Windows\ System32 и найдите файл c_1252.NLS, нажмите по нему правой кнопкой мыши, выберите пункт «Свойства» и откройте вкладку «Безопасность». На ней нажмите кнопку «Дополнительно».
- В поле «Владелец» нажмите «Изменить».
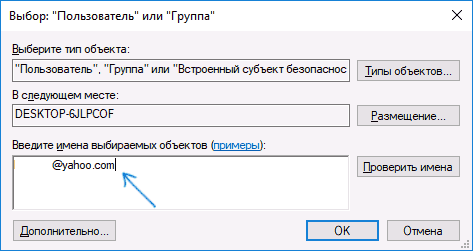
- В поле «Введите имена выбираемых объектов» укажите ваше имя пользователя (с правами администратора). Если в Windows 10 используется учетная запись Майкрософт, вместо имени пользователя укажите адрес электронной почты. Нажмите «Ок» в окне, где указывали пользователя и в следующем (Дополнительные параметры безопасности) окне.
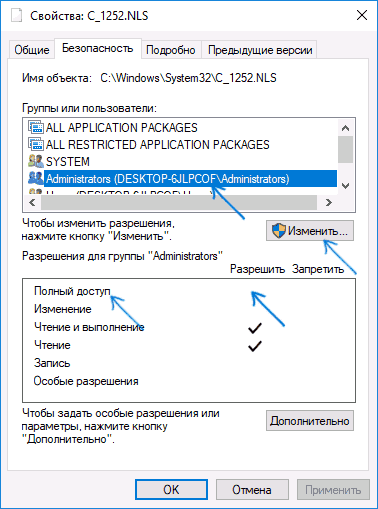
- Вы снова окажетесь на вкладке «Безопасность» в свойствах файла. Нажмите кнопку «Изменить».
- Выберите пункт «Администраторы» (Administrators) и включите полный доступ для них. Нажмите «Ок» и подтвердите изменение разрешений. Нажмите «Ок» в окне свойств файла.
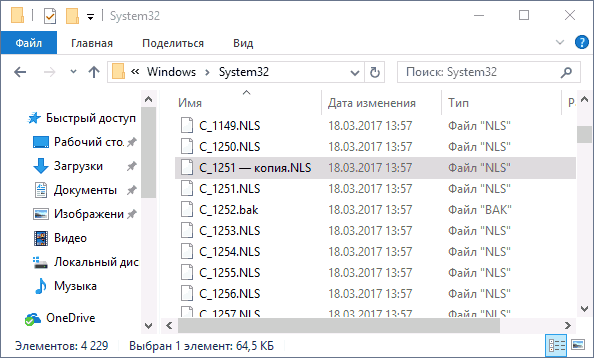
- Переименуйте файл c_1252.NLS (например, измените расширение на .bak, чтобы не потерять этот файл).
- Удерживая клавишу Ctrl, перетащите находящийся там же в C:\Windows\System32 файл c_1251.NLS (кодовая страница для кириллицы) в другое место этого же окна проводника, чтобы создать копию файла.
- Переименуйте копию файла c_1251.NLS в c_1252.NLS.
- Перезагрузите компьютер.
После перезагрузки Windows 10 кириллица должна будет отображаться не в виде иероглифов, а как обычные русские буквы.
HackWare.ru
Этичный хакинг и тестирование на проникновение, информационная безопасность
Как быстро узнать и преобразовать кодировку
Бывает, что в веб-браузере вместо читаемого текста показывается что-то вроде:
то есть совершенно нечитаемые символы.
Или так, когда английский символы показываются нормально, а вместо других символов знак процента и буквы с цифрами:
Бывают строки состоящие из больших и маленьких букв с цифрами, на конце может быть один или два знака равно:
Иногда приходится сталкиваться с текстом, в котором регулярно встречается обратный слэш с иксом (\x) после которого идут буквы и цифры:
Чтобы быстро расшифровать кодировку, даже когда вы не знаете как закодирована строка, воспользуйтесь бесплатным онлайн-сервисом по определению и преобразованию кодировки. Этот сервис скопирован отсюда http://0xcc.net/jsescape/.
Принцип работы очень простой — в окно вы вставляете строку в неизвестной кодировке, а сервис пытается преобразовать в каждую из поддерживаемых им кодировок. То есть если в поле Простой текст вы видите читаемый текст, значит ваша строка успешно расшифрована. Попробую понять смысл â ÐÑполниÑе Ð²Ñ Ð¾Ð´ или заÑегиÑÑÑиÑÑйÑеÑÑ:
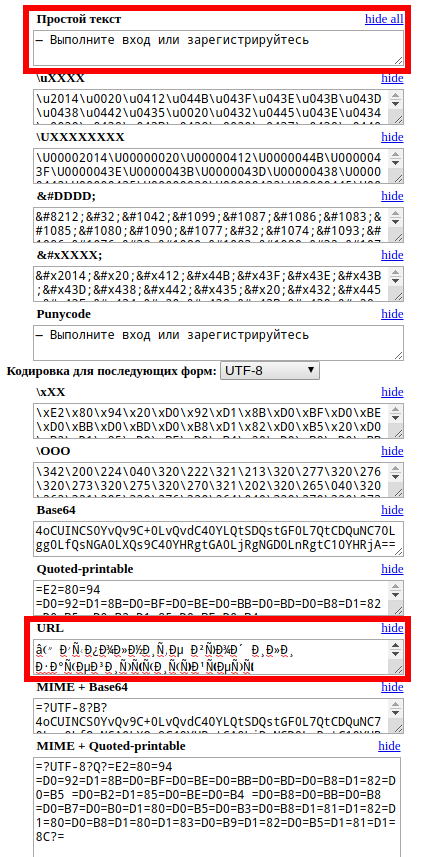
Получилось! Эта строка означает:
Теперь разберёмся со строкой:

Её значение оказалось:
А теперь посмотрим на сообщение из письма от мошенников:
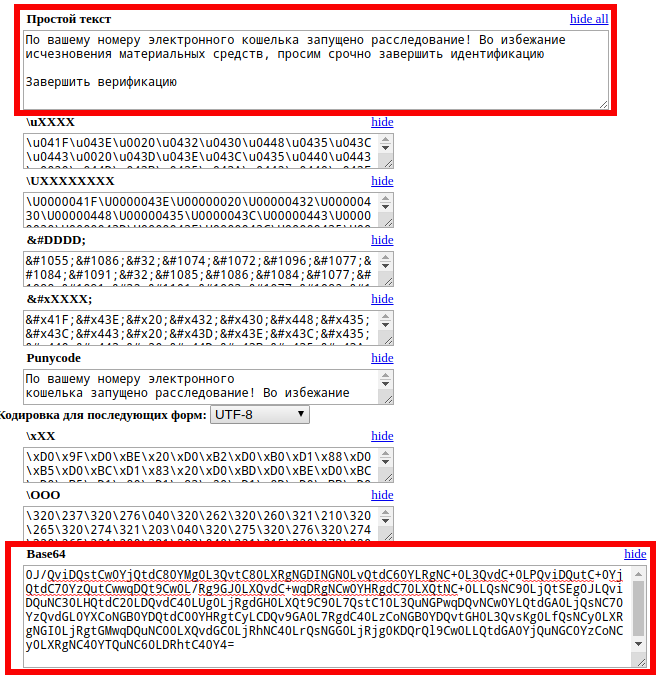
Как определить кодировку
Некоторые часто встречающиеся кодировки вполне можно определить «на глаз». Определение кодировки невооружённым глазом может сильно ускорить процесс расшифровки строки или быстрее понять причину, почему текст выведен в таком виде.
URL кодировка
Стандарт URL использует набор символов US-ASCII. Это имеет серьёзный недостаток, поскольку разрешается использовать лишь латинские буквы, цифры и несколько знаков пунктуации. Все другие символы необходимо перекодировать. Например, перекодироваться должны буквы кириллицы, буквы с диакритическими знаками, лигатуры, иероглифы. Перекодирующая кодировка описана в стандарте RFC 3986 и называется URL-encoding, URLencoded или percent‐encoding.
Данные из веб-форм, когда Content-Type указан как application/x-www-form-urlencoded также передаются в URL кодировке.
Base64
Я почти уверен, что вы когда-либо видели сообщения в этой кодировке — они пишутся большими и маленькими латинскими буквами, а также цифрами. На конце может быть один или два знака равно:
В любом случае, почти наверняка вы используете эту кодировку почти каждый день, даже сами того не зная, поскольку сообщения электронной почты очень часто используют Base64, особенно для писем, к котором приложены файлы (фотографии, документы и прочее).
Base64 — стандарт кодирования двоичных данных при помощи только 64 символов ASCII. Алфавит кодирования содержит текстово-цифровые латинские символы A-Z, a-z и 0-9 (62 знака) и 2 дополнительных символа, зависящих от системы реализации. Каждые 3 исходных байта кодируются 4 символами (увеличение на ¹⁄₃).
Эта система широко используется в электронной почте для представления бинарных файлов в тексте письма (транспортное кодирование).
Указанный сервис также умеет декодировать из Base64, а также кодировать в Base64, но имеется особенность: довольно часто длинная строка Base64 в email разбивается на строки одинаковой длины (по причинам удобства). В сервисе, на который дана ссылка, нужно убрать лишние переводы строк, то есть вводимые данные должны быть в одну строку, иначе после первого символа «новая строка» сообщение будет декодировано неверно.
Кодировка UTF-8
Неправильно отображаемая кодировка UTF-8 выглядит как большие буквы N и D с дополнительными линиями, встречаются дроби 3/4.
В данном случае кодировка UTF-8 обработана как кодировка ISO-8859-1 или CP1258. С помощью указанного сервиса такие строки можно расшифровать если скопировать их в окна Quoted-printable или URL.
UTF-8 кодировка обработанная как ANSI напоминает строки из больших букв P, C, Г и маленьких букв r и s:
Экранированные последовательности
Экранированные последовательности особенно часто можно увидеть в исходном коде программ. Если вы хотите узнать, что означает строка записанная таким образом, то скопируйте её в одно из полей:
- \uXXXX — обратный слэш и u за которыми идут буквы и цифры (шестнадцатеричное число)
- \UXXXXXXXX — обратный слэш и большая U за которыми идут буквы и цифры (шестнадцатеричное число)
- &#DDDD; — знак амперсанд и решётка, за которыми идут четыре цифры
- &#xXXXX; — знак амперсанд, решётка и x, за которыми следует шестнадцатеричное число
- \xXX — обратный слэш и x, за которыми следует шестнадцатеричное число
- \OOO — обратный слэш и большая O, за которыми идёт число в восьмеричной системе счисления.
Такие строки используются в ситуациях, когда есть опасность, что написанные буквами национального алфавита строки исказятся (например, браузер неправильно поймёт кодировку веб-страницы):
Как конвертировать в экранированные последовательности
На этой же странице, как уже можно догадаться, можно конвертировать и в саму экранированную последовательность символов.
Если вы хотите углубить своё понимание строк, познакомиться с непечатанными символами, узнать что такое управляющие символы, узнать о других формах записи строк и о выполнении с ними логических операций, то рекомендуется для расширения кругозора статья «ASCII и шестнадцатеричное представление строк. Побитовые операции со строками».
Как изменить кодировку строки или документа без сторонних сервисов
Хотя показанный выше сервис НЕ отсылает введённые данные на сервер, а обходится исключительно с помощью JavaScript, запущенном в браузере пользователя, вполне возможно, что вы хотите изменить кодировку не используя сайты.
Double Commander при просмотре текстовых файлов (для этого выделите файл и нажмите F3) или при редактировании (F4) вы можете после открытия изменить кодировку, а также сохранить с другой кодировкой.
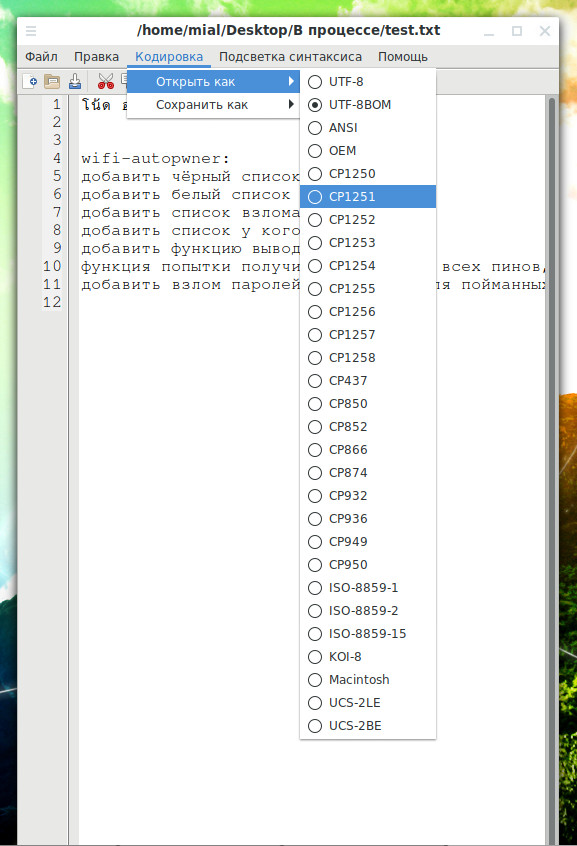
Ещё один вариант для тех, у кого Linux, — использовать командную строку. С помощью неё можно узнать кодировку непонятной строки, а также изменить её на правильную. Для этого смотрите статью «Как определить кодировку файла или строки. Как конвертировать файлы в кодировку UTF-8 в Linux».