- Как можно использовать прерываемые виртуальные машины Яндекс.Облака и экономить на решении масштабных задач
- Основные ограничения
- Сценарии использования
- Пакетная обработка данных
- Проекты на Hadoop
- Отказоустойчивость веб-сервисов
- Проекты на Kubernetes
- Тестирование в практике непрерывной интеграции
- Использование совместно с другими сервисами Яндекс.Облака
- Экономические показатели
- Подключение облачных хранилищ Яндекс.Диск, Google Диск и OneDrive в Linux CentOS
- Подключение Яндекс.Диска в Linux CentOS через WebDAV
- Подключение Google Диск (Google Drive) в качестве хранилища в Linux
- Подключение облачного хранилища OneDrive в Linux
Как можно использовать прерываемые виртуальные машины Яндекс.Облака и экономить на решении масштабных задач
Сегодня мы хотим рассказать о такой полезной функции Яндекс.Облака как прерываемые виртуальные машины. Это специальная опция, которую вы можете выбрать при создании виртуальной машины, чтобы использовать вычислительные ресурсы по сниженной цене. Что же такого особенного в прерываемых виртуальных машинах, почему они стоят дешевле обычных и в каких случаях разумно их применять?

Мощности Яндекс.Облака, а точнее, инфраструктурного сервиса Yandex Compute Cloud, заметно больше тех, что задействуются пользователями. По умолчанию предполагается, что у пользователей должна быть возможность условно неограниченного масштабирования. Как минимум из этих соображений, без учета других аспектов, доступные ресурсы облачной платформы существенно превышают текущий спрос. Именно на этих свободных мощностях и создаются прерываемые виртуальные машины.
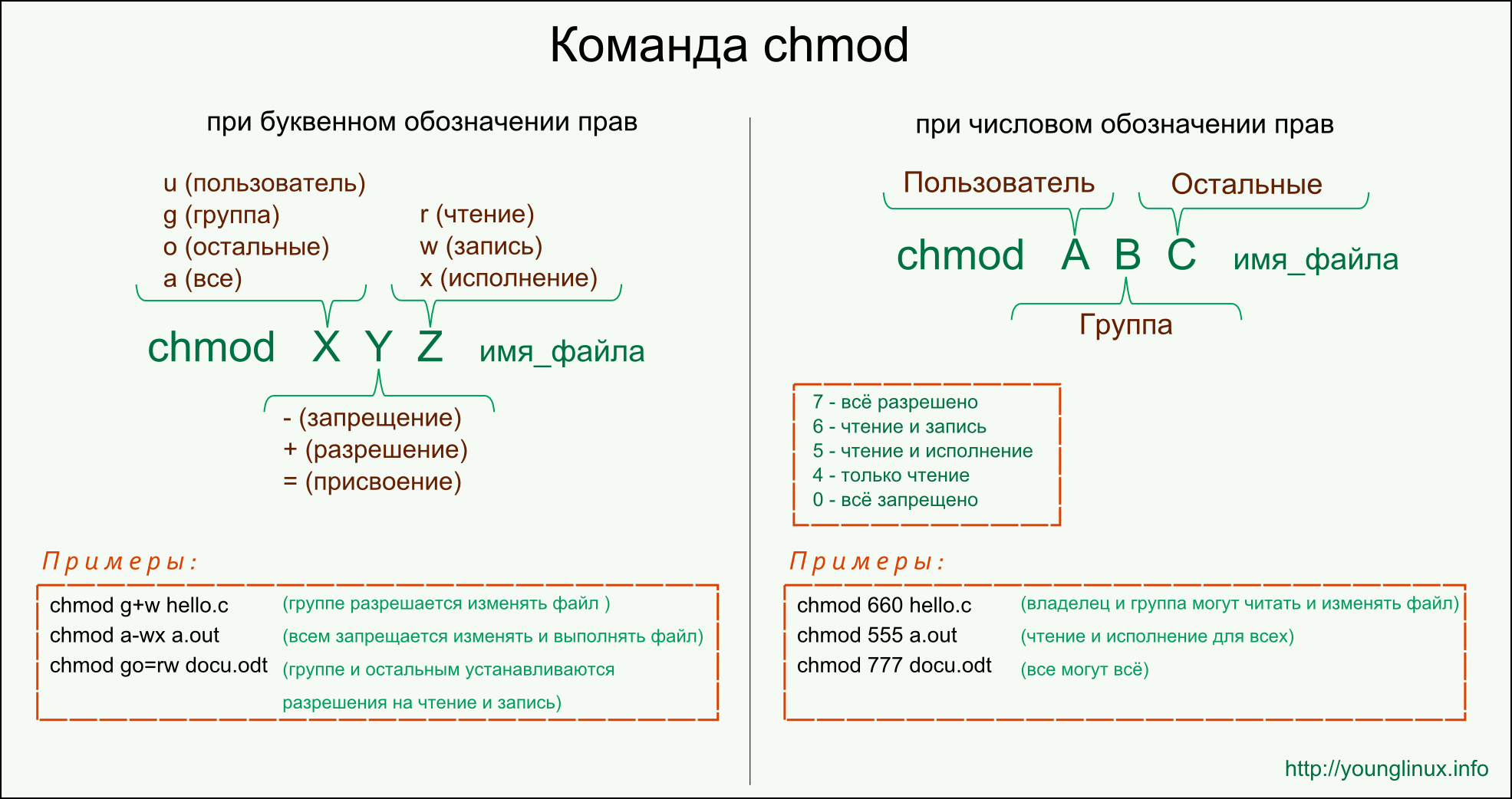
Основные ограничения
Коротко сущность прерываемых виртуальных машин можно описать так: сервис предлагает использовать свои свободные вычислительные ресурсы по меньшей цене при условии, что эти ресурсы могут быть отозваны в любой момент.
В целом прерываемые виртуальные машины работают как обычные виртуальные машины, но для них установлен ряд ограничений:
- На них не распространяется соглашение об уровне обслуживания (SLA).
- Не гарантируется возможность создания и запуска.
- Они могут быть принудительно остановлены в любой момент. Вероятность остановки невелика, однако не равна нулю, может меняться со временем и различаться в разных зонах доступности Яндекс.Облака.
- Прерываемую виртуальную машину нельзя сделать обычной, а обычную прерываемой. Соответствующий флаг устанавливается один раз и не меняется.
- Машина обязательно будет остановлена в срок, не превышающий 24 часа.
На практике в подавляющем большинстве случаев прерываемые виртуальные машины отрабатывают все 24 часа, предусмотренные условиями сервиса. Принудительная остановка, как правило, происходит только тогда, когда в конкретной зоне доступности за короткий период создается большое количество обычных виртуальных машин: появляется новый пользователь с серьезными потребностями или массово масштабируются текущие пользователи.
При этом остановленную виртуальную машину можно запустить снова: все данные на дисках сохраняются и при автоматическом и при ручном выключении.
Сценарии использования
Ограничения для прерываемых виртуальных машин вызывают логичный вопрос: как их применять, если ресурсы могут быть отозваны в любой момент? В качестве пояснения приведём несколько возможных сценариев использования.
Пакетная обработка данных
Пакетная обработка подразумевает параллельное исполнение большого количества ресурсоёмких заданий. Это может быть преобразование форматов файлов, обработка и распознавание изображений, ETL-операции. Суть в том, что при пакетной обработке существует очередь заданий и целый набор рабочих процессов (исполнителей), получающих задания из очереди. Если отдельный исполнитель, запущенный на прерываемой машине, остановится, задание будет просто передано следующему исполнителю. Другими словами, остановка одной или даже нескольких виртуальных машин не окажет существенного негативного влияния на процесс и результат обработки.
При пакетной обработке данных речь идет об использовании десятков виртуальных машин. Применение прерываемых машин даёт очень заметную экономию. Сейчас один из главных потребителей производительных прерываемых виртуальных машин с 32 ядрами – давний клиент Яндекс.Облака, компания «Сейсмотек». «Сейсмотек» занимается обработкой сейсмических данных, которые необходимы для разведки газовых и нефтяных месторождений. Сейсморазведка предполагает работу с большими объемами информации. Данные обрабатываются пакетным методом. Компания одновременно использует до 60 с лишним прерываемых машин: суммарно до 2000 vCPU и 4000 ГБ RAM.
Проекты на Hadoop
Hadoop используется для разработки и выполнения распределённых программ, работающих на кластерах из сотен и тысяч недорогих узлов. Предусмотренные в Hadoop механизмы репликации файлов и автоматического перезапуска задач, выполнявшихся на вышедших из строя узлах, обеспечивают устойчивость распределённой системы к отказам отдельных машин. Именно поэтому там, где применяется Hadoop, как минимум часть узлов спокойно может быть развёрнута на прерываемых виртуальных машинах. В случае их досрочной остановки задачи будут отправлены на другие узлы.
Отказоустойчивость веб-сервисов
Постоянную доступность веб-сервиса можно обеспечить с помощью кластера. Кластер состоит из двух и более серверов. Одна из его задач в приложении к веб-сервисам – обеспечить стабильную работу в момент пиковых нагрузок. Характерные примеры: сайты интернет-магазинов или спортивные сайты, где рост трафика привязан к определенным датам. Для магазинов это могут быть традиционные праздники или периоды скидок, а для сайтов спортивной тематики – дни событий, когда идут трансляции, публикуются обзоры и фотоотчёты. В такие моменты объем трафика может увеличиваться в разы.
Кластер должен справляться с наплывом посетителей, распределяя трафик по разным узлам. На период резкого, но непродолжительно роста нагрузки отказоустойчивость можно обеспечивать, добавляя серверы на прерываемых виртуальных машинах. Такой вариант обходится недорого и хорошо справляется со своей задачей. Важно соблюдать одно условие: подобный кластер обязательно должен быть гибридным, то есть включать в себя обычные виртуальные машины. В этом случае даже маловероятная остановка прерываемых машин не приведёт к отказу сервиса.
Проекты на Kubernetes
Kubernetes позволяет автоматизировать развёртывание, масштабирование и управление контейнеризированными приложениями на большом количестве узлов. Одна из основных сущностей, которую можно назвать строительным блоком Kubernetes, – под (pod). Под обеспечивает запуск одного или нескольких контейнеров на одном узле. Узел для каждого пода подбирается и назначается планировщиком Kubernetes. Если отдельный узел с запущенным подом выйдет из строя, планировщик автоматически перенесёт под на узел, работающий в штатном режиме. Такая схема поддержания работоспособности предполагает, что часть узлов можно размещать на прерываемых виртуальных машинах.
Тестирование в практике непрерывной интеграции
Практика непрерывной интеграции строится на частой сборке и тестировании проекта. При этом применяется в основном автоматизированное тестирование. Схематически это выглядит так: создаётся тестовое окружение на виртуальной машине, в него выгружается последний билд приложения, проводится автоматизированное тестирование, результаты тестирования выгружаются, виртуальная машина удаляется. Как правило, тестирование занимает несколько десятков минут, реже – несколько часов.
Традиционно слабыми местами непрерывной интеграции считаются значительные затраты на поддержку самого процесса интеграции и высокая потребность в вычислительных ресурсах. С этой точки зрения и с учетом временных рамок автоматизированных тестов прерываемые виртуальные машины выглядят более чем подходящим вариантом для непрерывной интеграции. Они намного дешевле, а вероятность остановки машины непосредственно в момент проведения тестирования исчезающе мала. Больше того, даже если машина всё-таки будет остановлена, ущерб с точки зрения бизнеса будет минимальным.
Использование совместно с другими сервисами Яндекс.Облака
Сервис Yandex Instance Groups позволяет в автоматическом режиме отслеживать состояние целой группы прерываемых виртуальных машин. Он может самостоятельно создавать виртуальные машины с заданными характеристиками, поддерживать нужное количество машин в группе и перезапускать прерываемые инстансы в случае их остановки. Неважно, произошла ли принудительная остановка или прошло 24 часа с момента запуска. Важно только одно: перезапуск произойдет, если есть доступные ресурсы. Yandex Instance Groups делает работу с прерываемыми виртуальными машинами удобнее, но не может гарантировать, что в конкретной зоне доступности обязательно будут свободные мощности.
Экономические показатели
Как мы упоминали, прерываемые виртуальные машины позволяют сокращать затраты на использование вычислительных ресурсов. Внутри Яндекса мы начали работать над реализацией подобной функции ещё несколько лет назад. Чтобы разделить вычислительные задачи на гарантированно исполняемые и прерываемые, потребовались немалые инвестиции. Но всё было не зря: в итоге мы повысили уровень полезной утилизации серверной инфраструктуры с 30-40% до 70-80%.
Теперь аналогичные возможности доступны всем пользователям Яндекс.Облака по нажатию одной кнопки. Простой пример: если вы переведёте половину используемых виртуальных машин со стопроцентной загрузкой ядра в формат прерываемых, то сможете сэкономить до 35-40% бюджета.
По сниженной стоимости доступны ресурсы CPU и RAM. Дисковое пространство и IP-адреса оплачиваются по обычным тарифам. Вот что показывает простой расчёт для платформы Cascade Lake.
При желании вы можете сами сравнить стоимость использования виртуальных машин в разных режимах с помощью калькулятора.
Надеемся, мы смогли внести немного ясности и дать несколько полезных примеров, в каких случаях можно применять прерываемые виртуальные машины, чтобы сократить расходы на вычислительные ресурсы, не теряя в качестве выполнения задач.
Источник
Подключение облачных хранилищ Яндекс.Диск, Google Диск и OneDrive в Linux CentOS
В этой статье мы рассмотрим, как подключить бесплатные облачные хранилища Яндекс.Диск, Google Диск и OneDrive в Linux CentOS для использования их под бэкапы или простого обмена файла между разными операционными системами. Например, вы можете установить клиент облачного хранилища у себя в Windows, загрузить в него файлы и автоматически получить доступ к ним из Linux (или наоборот).
Зачастую владельцы или веб-разработчики какого-либо ресурса, не задумываются, что при нехватке места на виртуальной машине или контейнере, можно воспользоваться облачными хранилищами. В своей работе я часто рекомендую пользователям, подключать тот же Яндекс.Диск к себе на VDS, чтобы хранить какие-то не часто используемые материалы или бэкапить туда сайт и базы MySQL/MariaDB.

В данной статье мы рассмотрим подключение наиболее распространненных бесплатных хранилищ Яндекс.Диск, OneDrive и Google Диск (Google Drive) на виртуальную машину с предустановленной ОС CentOS 7.
Подключение Яндекс.Диска в Linux CentOS через WebDAV
Рассмотрим, как подключить облачное хранилище Яндекс.Диск в Linux с помощью протокола WebDAV.
В этой инструкции мы подключим Яндекс.Диск как файловую систему к виртуальному серверу с Linux CentOS с помощью клиента davfs2. Покажем, как настроить автоматическое монтирование облачного хранилища Яндекс через автозагрузку.
Обычно пакет davfs2 уже должен быть установлен в системе, но может быть такое, что он не установился, поэтому делаем установку. Нужно подключить репозиторий Epel и установить сам пакет через yum:
yum install epel-release -y
yum install davfs2 -y
Проверяем, что модуль fuse на машине присутствует:
Вывод должен быть примерно таким:

Создаем отдельную директорию для нашего облачного хранилища:
После того, как все подготовительные работы выполнены, можем приступить к подключению Яндекс.Диск к серверу.
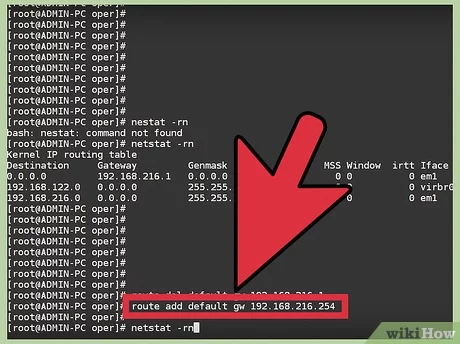
Монтируем Яндекс.Диск к созданной ранее директории:
mount -t davfs https://webdav.yandex.ru /mnt/yad/
После ввода команды, в консоли выйдут поля, где нужно будет указать ваш почтовый ящик на Яндексе и пароль от него
У меня диск подключился без проблем:
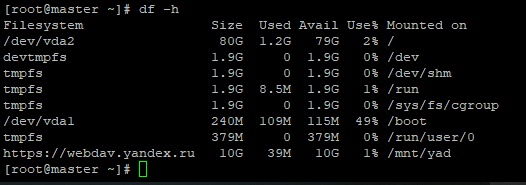
И сразу можно убедиться, что содержимое Яндекс.Диска теперь доступно в Linux:
[root@master yad]# ls -la /mnt/yad/
Создадим файл в подключеном WebDav каталоге файлы и проверим, что он появился в веб-версии Яндекс.Диска:
[root@master yad]# touch /mnt/yad/test.txt
[root@master yad]# ls -la /mnt/yad/
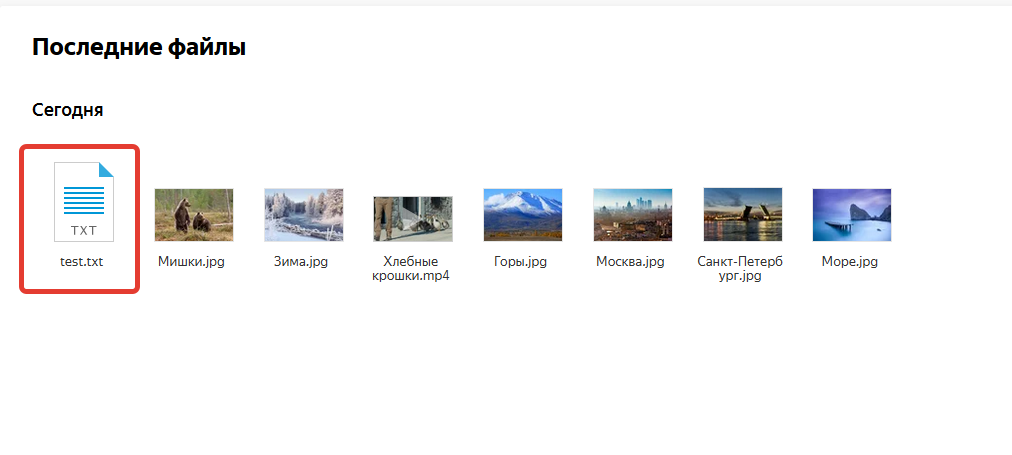
Файл появился, наше подключение к облачному хранилищу Яндекс.Диск работает нормально, локальный файл автоматически синхронизируется с облаком.
Для упрощения монтирования, добавим его в rc.local, чтобы после рестарта сервера, хранилище Яндекс.Диск монтировалось автоматически.
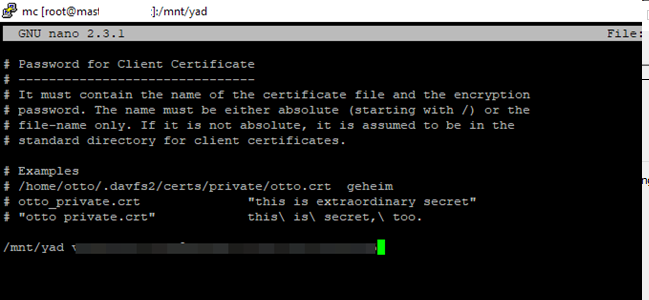
Для этого, создаем файл /etc/davfs2/secrets:
touch /etc/davfs2/secrets
и добавляем туда путь до директории, в которую монтируем Яндекс.Диск и логин/пароль пользователя Яндекс:
/mnt/yad user password
В rc.local добавляем следующую строку:
mount -t davfs https://webdav.yandex.ru /mnt/yad/
Делаем рестарт Linux и проверяем доступность облачного диска:
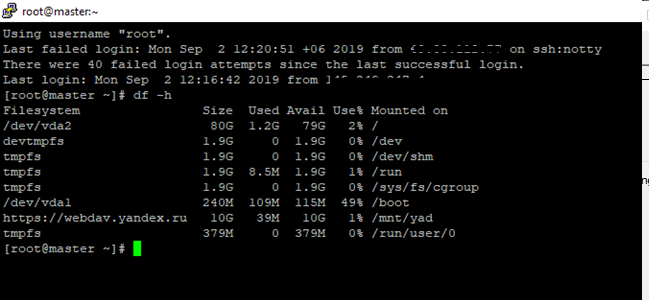
У меня после перезагрузки сервера, хранилище примонтировалось автоматически. Но иногда файл rc.local не читается при запуске сервера, в таком случае для автозапуска сервиса rc-local выполните следующие команды:
chmod +x /etc/rc.d/rc.local
systemctl enable rc-local
На этом настройка и подключение Яндекс.Диск в Linux CentOS завершена.
modprobe fuse — добавление модуля на ноду
vzctl set 101 —save —devnodes «fuse:rw» (где 101 это ID нужного контейнера) — добавление модуля к нужному контейнеру
И после данных манипуляций делаем рестарт контейнера.
Подключение Google Диск (Google Drive) в качестве хранилища в Linux
Рассмотрим как подключить облачное хранилище Google Диск (Google Drive) в Linux CentOS 7. Установка его очень простая и быстрая.
Загружаем клиент Google Drive подключить командой:
wget -O drive https://drive.google.com/uc?id=0B3X9GlR6EmbnMHBMVWtKaEZXdDg
Перемещаем файл директорию /usr/sbin командой:
mv drive /usr/sbin/drive
Даем права на файл:
chmod +x /usr/sbin/drive
На этом установка клиента Google Drive завершена, нам остается лишь запустить его и пройти авторизацию:
]# mv drive /usr/sbin/drive
[root@master
]# chmod +x /usr/sbin/drive
[root@master
Нужно скопировать ссылку и открыть ее в брузере на ПК, после чего разрешить доступ к аккаунту.
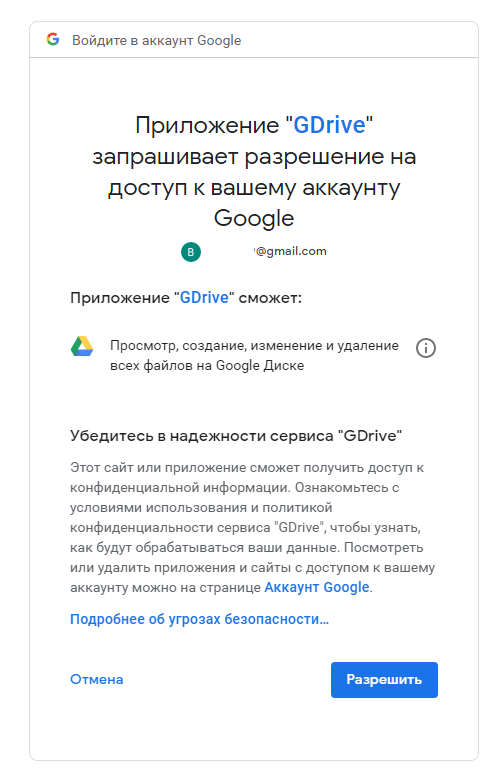
После этого, вам будет предоставлена ссылка, которую нужно будет ввести в консоли Linux:
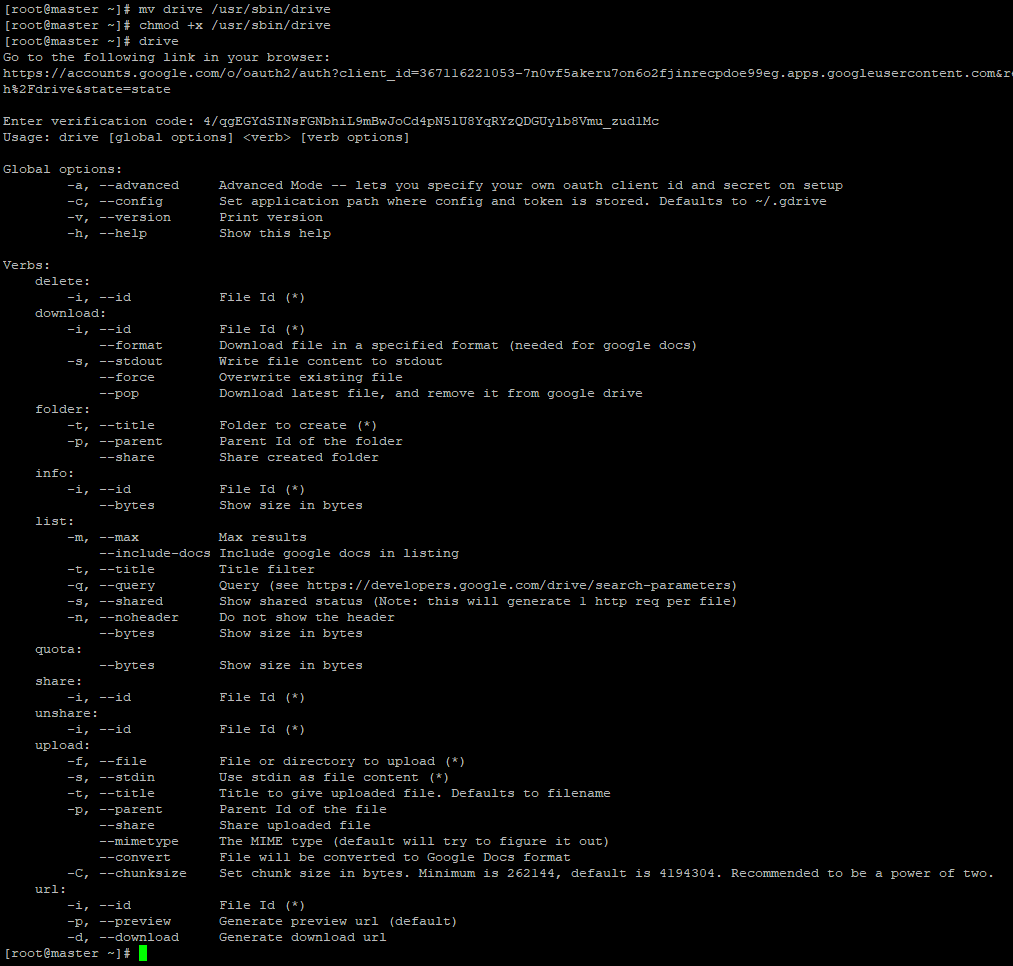
Google Drive подключен, однако он подключен не через WebDav (не поддерживается) , и вы не видите его как отдельную файловую систему и локальный каталог. Все обращения к хранилищу Google выполняются через клиент drive
Можно проверить какие файлы присутствуют на хранилище Google Диск командой drive list:
Файлы выводятся в виде таблицы с четырьмя столбцами:
- Id – уникальный код файла
- Title – название файла
- Size – размер
- Created – дата создания
Для теста можем создать файл и передать его на g.drive:
touch drive.txt && drive upload —file drive.txt
Файл создался, и виден в консоли:
Так же проверим, что файл появился в веб-интерфейсе Google Диск:
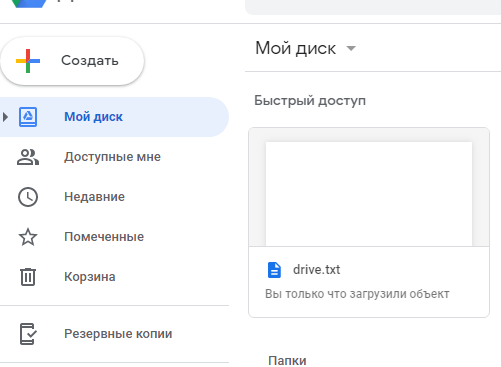
Как видим, файл на месте.
На этом подключение Google Диск к нашему серверу Linux окончено. В чем мне нравится Google Drive, так это в том, что не нужно выполнять какие-то дополнительные манипуляции на сервере, чтобы облачное хранилище монтировалось после перезагрузки сервера. Можно сколько угодно раз перезапускать ваш сервер, Google Drive будет подключаться автоматически. Но также есть свои минусы, например, на сервере мы не видим хранилище, как отдельную директорию и не можем управлять файлами на уровне файловой системы или привычными командами bash.
Подключение облачного хранилища OneDrive в Linux
OneDrive – облачное хранилище компании Microsoft. По умолчанию оно доступно для всех пользователей Windows 10 с привязанным аккаунтом (в хранилище OneDrive бесплатно предоставляется 5 Гб места). Наша задача подключить облачное хранилище OneDrive в CentOS 7. В процессе настройки я столкнулся с множеством проблем, которые путем научных экспериментов удалось решить. Вам же потребуется только ознакомиться с инструкцией и воспроизвести все действия у себя на сервере.
Для начала нам нужно зарегистрироваться по ссылке _https://onedrive.live.com
Процедуру регистрации я опущу, так как она не отличается от регистрации на любом другом ресурсе.
Теперь установим необходимые пакеты в Linux CentOS:
yum groupinstall ‘Development Tools’ -y
yum install libcurl-devel -y
yum install sqlite-devel -y
После этого установим язык программирования D(dlang), он потребуется для установки клиента OneDrive:
curl -fsS https://dlang.org/install.sh | bash -s dmd
Чтобы запустить среду D(dlang), введем команду:
/dlang/dmd-2.088.0/activate — в вашем случае версия dmd может отличаться, указываете свою.
Запустив dlang, мы проведем установку самого клиента OneDrive:
сd /opt
git clone https://github.com/abraunegg/onedrive.git
cd onedrive
./configure
make clean; make;
sudo make install
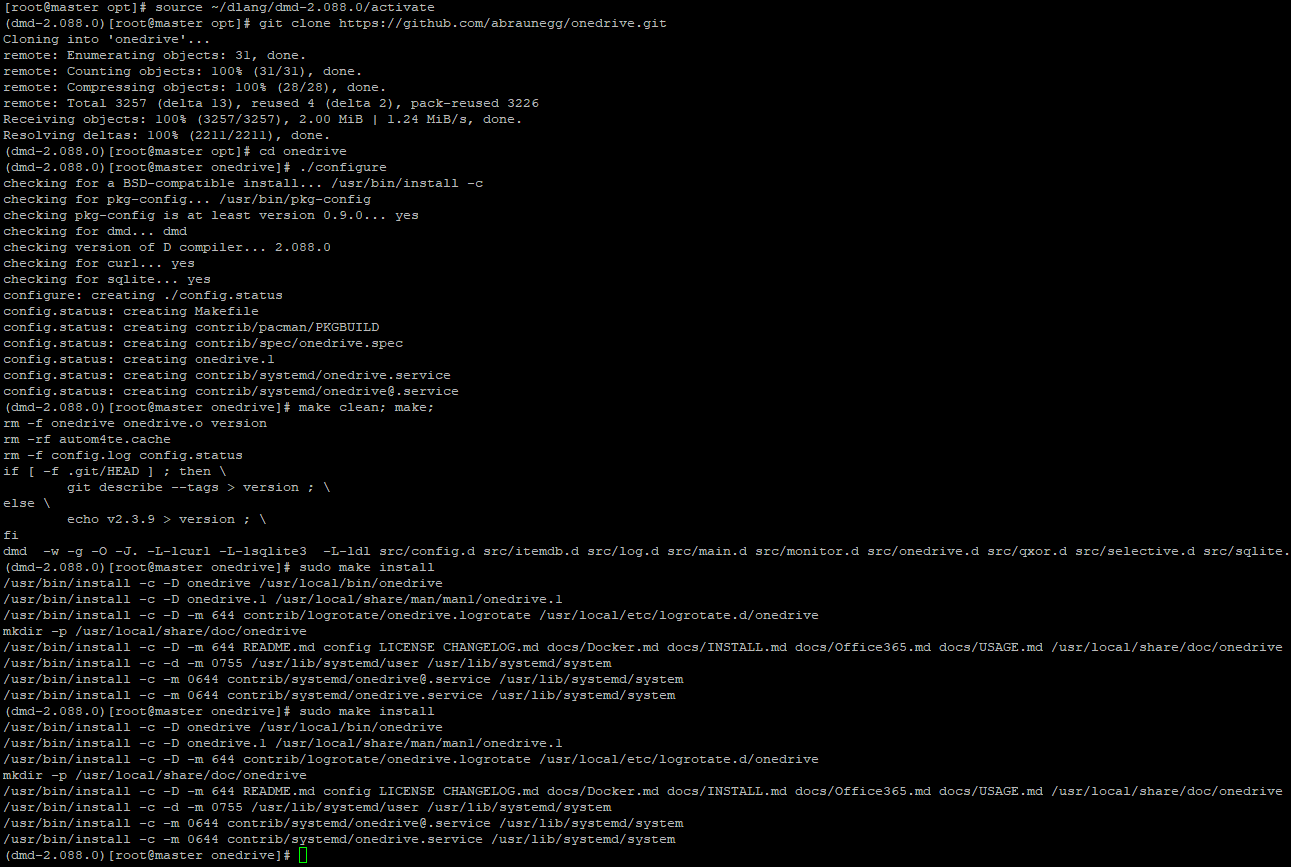
Установка завершена, теперь нужно пройти активацию в веб-версии OneDrive.
Система вам выдаст ссылку, которую нужно ввести в браузере. В веб форме с запросом доступа нужно нажать кнопку Разрешить. После этого ссылка изменится уникальную с кодом, которую и нужно будет ввести в консоли Linux. У меня сформировалась такая ссылка https://login.microsoftonline.com/common/oauth2/nativeclient?code=M74bb67a8-f9a6-1a26-e345-c45a3324de49 :
(dmd-2.088.0)[root@master onedrive]# onedrive
После подтверждения ссылки, я могу выполнить синхронизацию с облачным хранилищем OneDrive:
(dmd-2.088.0)[root@master onedrive]# onedrive —synchronize
По умолчанию, у меня создалась директория /root/OneDrive, в которой появились все каталоги моего облачного хранилища.
(dmd-2.088.0)[root@master OneDrive]# ls -la /root/OneDrive/
Для теста я создал файл test2.txt и выполнил синхронизацию:
[root@master backup]# onedrive —synchronize
Файл закачался в облако Microsoft:
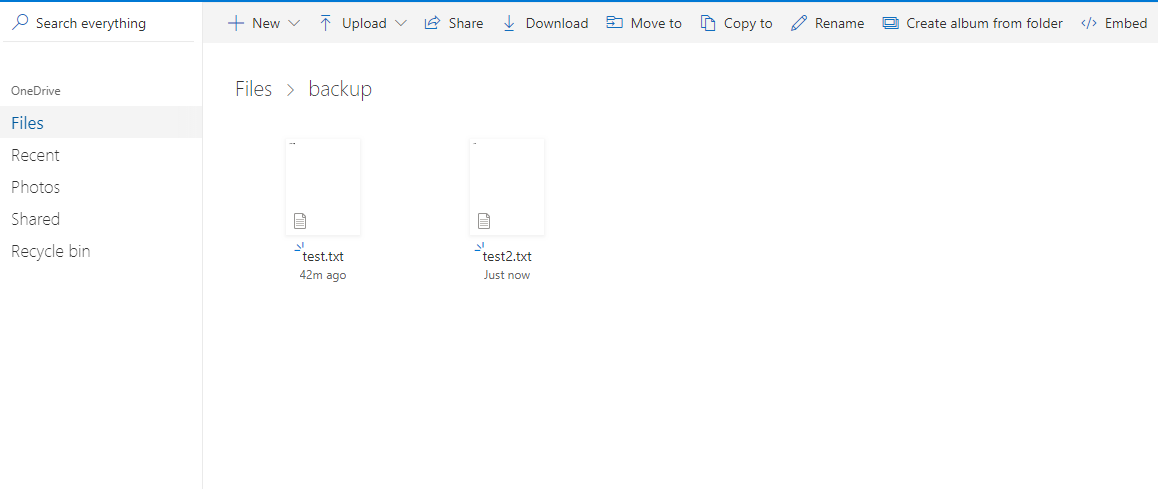
Чтобы изменить директорию по умолчанию, нужно в конфигурационном файле изменить параметр sync_dir и после этого запустить команду:
onedrive —synchronize —resync
После перезагрузки сервера, клиент OneDrive запускает автоматически и не нужно повторно проходить авторизацию.
На этом настройка OneDrive на сервере с CentOS 7 окончена, надеюсь, что информация будет для многих полезна. В следующей статье мы рассмотрим, как использовать облачные хранилища для бэкапа данных с Linux сервера.
Источник